
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 클라우드
- namespace
- 빅데이터
- ResourceQuota
- daemonset
- k8s
- 도커
- 고가용성
- docker
- dns
- 해커톤
- 네트워크 가상화
- cronjob
- 온프레미스
- Replicaset
- 웹 스토리지
- 해시
- 혼잡제어
- configmap
- 리소스 풀링
- goorm
- Urn
- Web
- 하둡
- OverTheWire
- 다중화
- 클라우드 네이티브 5회차
- 핸드셰이크
- 네트워크
- LimitRange
Archives
- Today
- Total
NakedFlower 님의 블로그
하둡 파일 시스템 본문
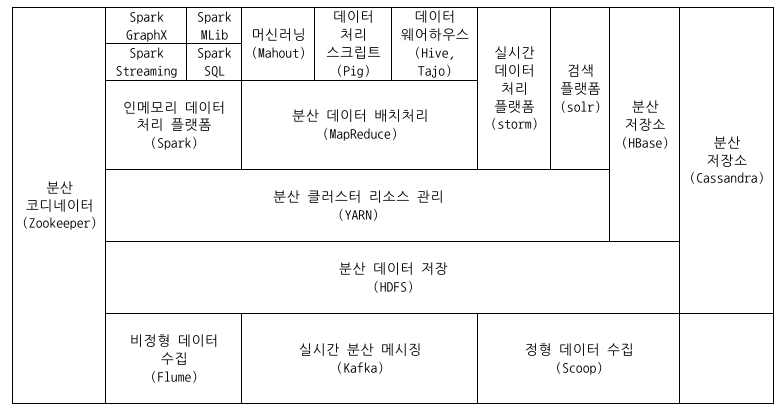
| 기능 | 프로젝트 이름 | 개요 |
| 분산 코디네이터 | 주키퍼 (Zookeeper) | 서비스 분산과 서버 간 상황을 관리하며 분산 서버의 통합환경 관리 |
| 데이터 수집 | Flume | 분산된 서버에서 생성된 로그 타입의 비정형 데이터를 수집 |
| Kafka | 실시간 분산환경에서 메시지를 송수신하는 메시지 전달 솔루션 | |
| Scoop | HDFS, RDBMS, NoSQL 에서 정형화된 데이터를 수집 | |
| 분산 데이터 저장 | Hadoop Distribute File System (HDFS) |
하둡 클러스터 환경에 분산 저장하는 솔루션으로 Namenode 와 Datanode 로 관리 |
| 분산 클러스터 관리 | YARN | 분산 클러스터의 리소스 관리 솔루션으로 Resource Manager 가 Node Manager 를 관리하는 구조 |
| 분산 데이터 배치처리 | Hadoop MapReduce | Map 과 Reduce 의 2상(phase)로 데이터를 처리하는 하둡 기반의 배치(batch) 작업 플랫폼 |
| 인메모리 데이터 처리 | Apache Spark | 인메모리 상에서의 데이터 처리 플랫폼으로 배치처리, 실시간 스트리밍, SQL 질의와 Graph 처리, 머신러닝 같은 하위 프로젝트를 사용 |
| 데이터 처리 | Pig | 맵리듀스를 처리할 수 있는 스크립트 언어 생성 및 처리 솔루션 |
| Mahout | 하둡 기반의 데이터 마이닝 알고리즘을 지원하는 솔루션 | |
| 데이터웨어하우스 연동 | Hive | 하둡 기반의 데이터 웨어하우스 시스템 |
| 실시간 데이터처리 | Storm | 하둡 클러스터 기반의 실시간 데이터 처리 솔루션 |
| 검색엔진 플랫폼 | Solr | 하둡 기반의 검색엔진 |
| 데이터 저장 | HBase | 실시간 조회와 업데이트가 가능한 칼럼 기반의 NoSQL 저장소 |
| Cassandra | 자체로 구현된 링(Ring) 구조와 키/값 칼럼 기반의 NoSQL 저장소. SQL과 유사한 CQL 쿼리 사용 |
하둡이 유용하게 사용되는 이유
- 스케일 아웃이 가능한 저비용의 저장소(HDFS)를 사용할 수 있어서
- 다양한 데이터 타입(정형/반정형/비정형 데이터)을 모두 다룰 수 있어서
- 분산 클러스터 환경에서도 장애에 효율적으로 대체할 수 있어서
- 대규모 빅데이터를 적용하여 데이터를 모델링하고 분석할 수 있어서
- 빅데이터 해석을 위한 딥러닝에서 인공지능 시스템이 더 정확하고 올바른 가중치와 편향을 얻을 수 있도록 양질의 학습 데이터를 공급할 수 있다.
'Data Engineering' 카테고리의 다른 글
| 빅데이터 개론 (0) | 2025.10.31 |
|---|---|
| Apache Kafka (0) | 2025.10.30 |
'Data Engineering' Related Articles
more

