
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 클라우드
- cronjob
- k8s
- daemonset
- 고가용성
- 빅데이터
- 다중화
- Urn
- 해시
- 리소스 풀링
- Replicaset
- docker
- 혼잡제어
- configmap
- Web
- goorm
- 온프레미스
- 네트워크 가상화
- 네트워크
- 핸드셰이크
- dns
- LimitRange
- ResourceQuota
- 클라우드 네이티브 5회차
- namespace
- 하둡
- OverTheWire
- 웹 스토리지
- 해커톤
- 도커
Archives
- Today
- Total
NakedFlower 님의 블로그
고가용성, 이중화, 다중화, 로드밸런싱 본문
안정성을 위한 기술
- 안정성을 수치로 표현하는 가용성
- 안정성을 높이기 위한 방법
-> 이중화와 다중화 - 물리적 장비나 프로그램 등을 여러 개 두는 기술
-> 로드 밸런싱 - 트래픽을 고르게 분산하는 기술
안정성을 수치로 표현하는 가용성
가용성(availability)
- 컴퓨터 시스템이 특정 기능을 실제로 수행할 수 있는 시간의 비율
- 전체 사용 시간 중에서 정상적인 사용 시간
- 업타임(uptime) - 정상적인 사용 시간
- 다운타임(downtime) - 정상적인 사용이 불가능한 시간
- 가용성 = (업타임) / (업타임 + 다운타임)
- 고가용성(HA, High Availability)
- 가용성이 높음
- 일반적으로 '안정적'인 시스템 99.999% 이상을 목표
| 가용성(%) | 1년간 다운타임 | 한 달간 다운타임 | 한 주간 다운타임 |
| 90% | 36.53일 | 73.05시간 | 16.8시간 |
| 99% | 3.65일 | 7.31시간 | 1.68시간 |
| 99.5% | 1.83일 | 3.65시간 | 50.4분 |
| 99.9% | 8.77시간 | 43.83분 | 10.08분 |
| 99.95% | 4.38시간 | 21.92분 | 5.04분 |
| 99.99% | 52.56분 | 4.38분 | 1.01분 |
| 99.999% | 5.26분 | 26.3초 | 6.05초 |
| 99.9999% | 31.56초 | 2.63초 | 0.604초 |
| 99.99999% | 3.16초 | 0.262초 | 0.0604초 |
가용성을 높일려면 = 안정성을 높일려면
- 다운타임을 낮추면 된다
- 서비스는 왜 다운될까? -> 과도한 트래픽 -> 예기치 못한 소프트웨어 상의 오류 -> 하드웨어 장애 -> 보안 공격이나 자연재해 등등
- 원천적으로 차단할 수 없음
- 핵심은 문제가 발생하지 않도록 하는 것이 아니라, 문제가 발생해도 계속 기능하도록 설계하는 것
- 결함 감내(fault tolerance)
- 문제가 발생하더라도 기능할 수 있는 능력
- 결함을 감내할 수 있도록 서비스나 인프라를 설계하는 것이 중요
이중화
- 결함을 감내하여 가용성을 높이기 위한 가장 기본적이고 대표적인 방법
- '예비(백업)을 마련하는 방법'
- 무엇을 이중화해야 할까?
- '문제가 발생할 경우 시스템 전체가 중단될 수 있는 대상'
- 서버 컴퓨터, 네트워크 인터페이스(NIC), 스위치와 같은 물리적 장비
- 데이터베이스, 웹 서버 프로그램 등
문제가 발생할 경우 시스템 전체가 중단될 수 있는 대상 = SPOF(single point of failure)
- 구성 방법
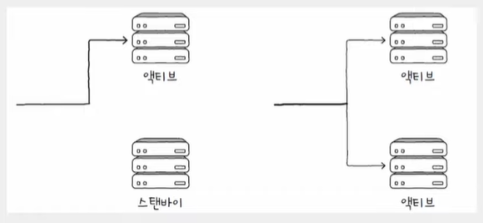
- 액티브/스탠바이(active-standby)
- 한 시스템은 가동하고, 다른 시스템은 백업 용도로 대기 상태(스탠바이)
- 액티브/액티브(active-active)
- 두 시스템 모두를 가동 상태
- 액티브/스탠바이(active-standby)
이중화/다중화의 사례, 티밍(teaming)과 본딩(bonding)
- 티밍(teaming) - 윈도우
- 본딩(bonding) - 리눅스
- 여러 네트워크 인터페이스(NIC)를 이중화/다중화하여 더 뛰어나고 안정적인 성능의 하나의 인터페이스처럼 보이게 하는 기술
로드 밸런싱
- 고가용성을 요구하는 호스트는 클라이언트보다는 일반적으로 서버
- 서버 입장에서 가용성을 더 생각해보자
- 서버를 다중화했다면 무조건 안정적일까?

- 로드 밸런싱(load balancing), 트래픽의 고른 분배를 위한 기술
- 로드 밸런서(load balancer)에 의해 수행
- 전용 네트워크 장비('L4 스위치', 'L7 스위치')로 수행
- L4 스위치는 IP 주소와 포트 번호와 같은 전송 계층까지의 정보를 바탕으로 로드 밸런싱
- L7 스위치는 URI, HTTP 메시지 일부, 쿠키 등 응용 계층의 정보까지 활용하여 로드 밸런싱
- 로드 밸런싱 소프트웨어를 설치하면 일반 호스트로 로드 밸런서로 사용 가능
- HAProxy, Envoy 등
- Nginx에도 로드 밸런싱 기능이 내포
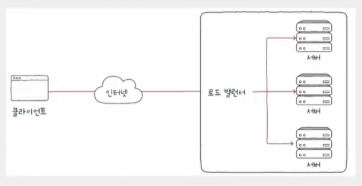
- 로드 밸런서의 위치
- 일반적으로 이중화/다중화된 서버와 클라이언트 사이에 위치
- 클라이언트들은 로드 밸런서에 요청을 보내고, 로드 밸런서는 해당 요청을 각 서버에 균등하게 분배
서버의 상태를 검사하는 헬스 체크
- 헬스 체크(health check)
- 서버들의 건강 상태를 주기적으로 모니터링하고 체크
- 주로 로드 밸런서에 의해 이루어짐
- HTTP, ICMP 등 다양한 프로토콜을 활용
- 서버 간 하트비트(heartbeat)라는 메시지를 주기적으로 주고받는 방법도 있음
부하 대상을 선택하는 알고리즘(로드 밸런싱 알고리즘)
로드 밸런싱 알고리즘
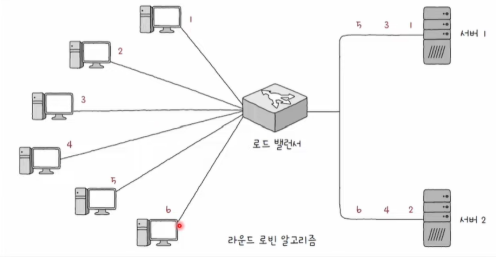
- 라운드 로빈 알고리즘(round robin algorithm)
- 단순히 서버를 돌아가며 부하를 전달
- 최소 연결 알고리즘(least connection algorithm)
- 연결이 적은 서버부터 우선적으로 부하를 전달
- 기타
- 단순히 무작위로 고르는 알고리즘
- 해시(hash) 자료 구조를 이용하는 알고리즘
- 응답 시간이 가장 짧은 서버를 선택하는 알고리즘
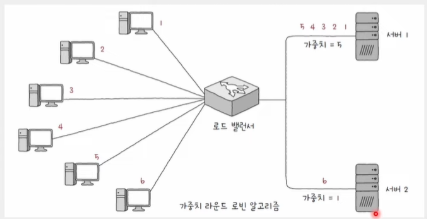
가중치가 부여된 알고리즘
- 가중치 라운드 로빈 알고리즘(weighted round robin algorithm)
- 가중치 최소 연결 알고리즘(weighted least connection algorithm)
- 서버 간 성능이 다른 경우 주로 가중치가 적용된 알고리즘 유리
포워드 프록시와 리버스 프록시
- 중간 서버와 다중화된 오리진 서버
- 클라이언트와 일반적으로 단일 서버와 나란히 붙어 있지 않음
- 실제로는 클라이언트와 서버 사이에는 수많은 서버가 존재할 수 있음
- 실제로는 서버가 다중화된 경우가 많음
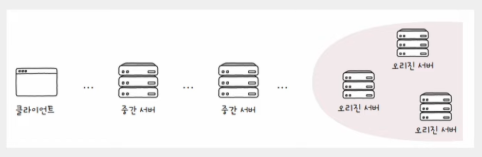
- 기존에 단순히 '서버'라 지칭한 대상
- 클라이언트가 최종적으로 메시지를 주고받는 대상
- 자원을 생성하고 클라이언트에게 권한있는 응답을 보낼 수 있는 HTTP 서버
- 오리진 서버(origin server)
- 인바운드 메시지 : 오리진 서버를 향하는 메시지
- 아웃바운드 메시지 : 클라이언트를 향하는 메시지
- 중간 서버의 종류와 역할
- 중간 서버의 유형 -> 프록시 : 포워드 프록시 -> 게이트웨이 : 리버스 프록시
- 프록시
- 클라이언트가 선택한 메시지 전달 대리자
- 프록시를 언제 어떻게 사용할지는 클라이언트가 선택
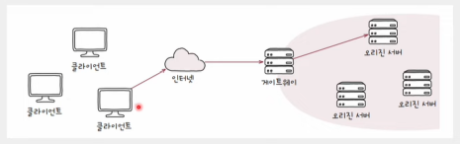
- 게이트웨이
- 일반적 의미 : 네트워크 간의 통신을 가능케 하는 입구 역할을 하는 HW/SW
- 'HTTP 중간 서버' 맥락에서의 의미 -> 아웃바운드 연결에 대해 오리진 서버 역할을 수행하는 중개자 -> 수신된 요청 메시지를 다른 인바운드 서버(들)에 전달하는 중개자
- 클라이언트가 보기엔 오리진 서버와 같이 보임
- 클라이언트가 요청을 오리진 서버에 전달하기 위해 오리진 서버(들)에 더 가까이 위치
- 캐싱, 로드 밸런싱
'CS > 네트워크' 카테고리의 다른 글
| 무선 네트워크 (0) | 2025.10.04 |
|---|---|
| 네트워크 인증 (0) | 2025.10.04 |
| HTTP 기반 기술 (1) | 2025.10.04 |
| HTTP에 대하여 (0) | 2025.10.04 |
| Domain Name Server (0) | 2025.10.03 |
'CS/네트워크' Related Articles
more



